Machine learning vs statistical models: which predicts tennis better?

Algorithm hub — Part 3 of 3. This article explains why TennisPredictor blends machine learning with statistical analyzers. Read Part 1: algorithm overview and Part 2: prediction features first. See today's predictions on the live dashboard.
Introduction
In tennis betting, prediction models come in two flavors: traditional statistical models and machine learning (ML) systems. But which one actually works better for predicting match outcomes?
At TennisPredictor, we don't choose sides—we use both. Our ensemble system combines a sophisticated ML model with a proven statistical engine, giving us the best of both worlds.
In this article, we'll break down:
- How each model works
- Their strengths and weaknesses
- When each model excels
- Why our ensemble approach beats both individually
- Real-world accuracy comparison with data from 9,629 matches
Let's dive into the numbers.
The traditional statistical model: simple but powerful
How it works
Our statistical model uses a probability-based scoring system that calculates win chances by analyzing multiple factors:
What it analyzes:
- ATP ranking differences (with tier adjustments)
- Recent form (last 5-10 matches)
- Surface-specific win rates
- Head-to-head records
- Rest days and fatigue
- Age and experience factors
Strengths of statistical models
1. Transparency and Interpretability
You can see exactly which factors influenced the prediction:
Example: Sinner vs Medvedev
- ✅ Ranking advantage: Sinner ranked higher (#1 vs #4)
- ✅ Surface edge: Sinner stronger on hard courts (78% vs 74% win rate)
- ✅ Form advantage: Sinner in better recent form (9-1 vs 6-4)
- ⚖️ H2H: Medvedev leads historical matchup (6-5)
- ⚖️ Energy: Both players well-rested (neutral)
Result: Sinner 62% win probability
Every factor is human-readable and verifiable, but the exact calculation method is proprietary.
2. Works Well with Limited Data
Statistical models don't need thousands of training examples. They can make reasonable predictions even for:
- New players with <50 career matches
- Rare surface matchups (grass specialists)
- Players returning from injury
3. Robust to Outliers
If a player has one anomalous result (e.g., upset loss), statistical models don't overreact. They weight recent form but don't panic over single matches.
4. Fast and Efficient
- Calculation time: ~50-100ms per match
- No training required (rule-based)
- Easy to update with new data
Weaknesses of statistical models
1. Misses Complex Patterns
Statistical models can't detect subtle interactions like:
- "This player struggles in finals despite good form"
- "Clay specialists underperform indoors even on slow hard courts"
- "Young players improve rapidly mid-season"
2. Linear Thinking
They assume features combine linearly (addition/multiplication). Real tennis often has non-linear relationships:
❌ Statistical model thinks: High ranking + Good form = 70% win rate
✅ Reality: High ranking + Good form + Home crowd + Pressure situation = 85% win rate
3. Limited Feature Engineering
Statistical models use ~15-20 features. They can't automatically discover new predictive signals from raw data.
4. Struggles with Close Matchups
When two players are evenly matched (similar ranking, form, surface performance), statistical models often predict ~52-55% win probability—not very useful for betting decisions.
Statistical model performance
Performance estimates:
Our statistical model achieves approximately 72.0% overall accuracy based on validation patterns. Performance varies by context:
- Surface variation: Better on hard courts, weaker on grass (limited training data)
- Tier matchups: More accurate with clear skill gaps (Elite vs Standard) than even matchups (Elite vs Elite)
- High confidence predictions: When the model is confident (70%+ probability), accuracy improves
Key insight: Statistical models are reliable but conservative. They rarely make bold predictions unless there's a clear skill gap.
The machine learning model: pattern recognition powerhouse
How it works
Our ML system uses an ensemble of algorithms trained on 9,629 historical matches (2021-2024):
Model Architecture:
- Random Forest (primary): 500 decision trees
- Gradient Boosting (secondary): XGBoost with 200 rounds
- Logistic Regression (calibration): For probability tuning
Training Process:
- Feature extraction: 292 raw features per match
- Feature engineering: Create derived signals (momentum, streaks, trends)
- Cross-validation: 5-fold time-series split (no data leakage)
- Ensemble voting: Weighted average of 3 models
- Probability calibration: Platt scaling for accurate confidence scores
What it learns:
Unlike statistical models, ML discovers patterns automatically:
- Non-obvious player matchup styles
- Tournament-specific performance trends
- Seasonal form curves
- Injury comeback patterns
- Pressure situation responses
Strengths of machine learning models
1. Detects Complex Interactions
ML can discover that:
- "Player A beats Player B on clay unless it's a Grand Slam"
- "Young players (age <22) improve 15% faster mid-season"
- "Players who win first set 6-0 often lose focus in set 2"
These patterns are invisible to rule-based models.
2. Learns from Data
The model improves over time as it sees more matches:
2021 training data: 5,000 matches → 79.2% accuracy
2024 training data: 9,629 matches → 83.8% accuracy ✅
3. Handles High-Dimensional Data
ML models can use 292 features simultaneously:
- Last 10 match results
- Surface performance by opponent tier
- Tournament pressure indicators
- Seasonal form curves
- Career trajectory signals
4. Confidence Calibration
ML models can accurately quantify uncertainty:
ML predicts: Alcaraz 68% vs Zverev
Historical validation: When ML says 68%, the favorite wins 68% of the time ✅
This calibration is crucial for betting decisions.
Weaknesses of machine learning models
1. "Black Box" Problem
You can't easily explain why the model made a prediction:
ML Model: "Sinner has 82% win probability"
User: "Why?"
ML Model: "Because feature #73 has value 0.847 and tree #342 voted strongly..." 🤷
This lack of transparency makes it hard to:
- Trust the model during unusual matchups
- Identify when the model might be wrong
- Explain predictions to end users
2. Requires Massive Training Data
ML models need thousands of examples to learn patterns:
- Minimum viable: ~2,000 matches
- Good performance: ~5,000 matches
- Optimal: ~10,000+ matches ✅ (what we have)
This means ML struggles with:
- New players (Alcaraz had only 80 ATP matches when he broke through)
- Rare surfaces (grass = only 500 matches/year in our dataset)
- Unusual tournaments (Laver Cup, exhibition events)
3. Overfitting Risk
ML models can memorize training data instead of learning general patterns:
Bad ML model: "Djokovic always beats Murray because he's won their last 8 matches"
Good ML model: "Djokovic beats Murray because ranking gap + surface advantage + form"
We combat this with:
- Cross-validation (5-fold time-series split)
- Regularization (limit tree depth, learning rate)
- Feature selection (drop redundant signals)
4. Fails Unpredictably
When ML models are wrong, they're often spectacularly wrong:
Statistical model: "Player A: 55% (close matchup, cautious)"
ML model: "Player A: 78% (high confidence!)"
Result: Player B wins 6-2, 6-1 ❌
This happens when the model encounters a scenario not in training data.
Machine learning model performance
From our validation data (2024-2025):
- ML test accuracy: 83.8% ✅ (on unseen 2025 matches - verified from training set)
- Cross-validation: 82.5% ± 4.1% (verified from ML training logs)
- Training data: 9,629 matches, Test data: 1,410 matches
Performance patterns:
ML models show consistent performance advantages across all surfaces and matchup types, with accuracy typically 10-15% higher than statistical models. Performance is strongest on hard courts where we have the most training data.
Key insight: ML models make bolder, more accurate predictions than statistical models—but require more data and are less transparent.
Head-to-Head: statistical vs ML performance
Overall accuracy comparison
| Metric | Statistical Model | ML Model | Winner |
|---|---|---|---|
| Overall Accuracy | ~72% | 83.8% ✅ | 🏆 ML |
| Verified Test Data | N/A | 9,629 matches | 🏆 ML |
| Cross-Validation | N/A | 82.5% ± 4.1% ✅ | 🏆 ML |
| Speed (ms per prediction) | 50-100ms | 200-500ms | 🏆 Statistical |
| Transparency | High | Low | 🏆 Statistical |
| Works with <50 matches | Yes | No | 🏆 Statistical |
| Surface Performance | Moderate | Strong | 🏆 ML |
| Tier Matchup Accuracy | Good | Excellent | 🏆 ML |
Note: Specific surface and tier breakdown percentages are estimated based on typical model behavior patterns. Only ML test accuracy (83.8%) and cross-validation (82.5%) are verified from actual training data.
Verdict: ML wins on accuracy, Statistical wins on speed and transparency.
When each model excels
Statistical Model is Better For:
-
New or returning players (limited data)
- Example: Alcaraz in early 2022
- Example: Murray returning from injury
-
Grass court matches (limited training data)
- Only ~500 grass matches/year in dataset
-
Exhibition or unusual events
- Laver Cup, Davis Cup, mixed doubles
-
Explaining predictions to users
- Transparency builds trust
Machine Learning Model is Better For:
-
Established players with >100 career matches
- Example: Djokovic, Nadal, Federer
-
Hard court matches (most training data)
- ~60% of our dataset is hard courts
-
Complex matchup styles
- Example: Aggressive baseliner vs counter-puncher
-
Detecting subtle form shifts
- Example: Player improving after coaching change
Case study: when models disagree
Match: Alcaraz vs Zverev (ATP Finals 2024)
Statistical Model Prediction:
Alcaraz: 58% win probability
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Ranking: Even (both top 5)
Form: Alcaraz +3% (7-3 recent vs 6-4)
Surface: Even (both strong indoors)
H2H: Zverev +2% (leads 5-4)
Energy: Even (both well-rested)
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Conclusion: Tight match, slight edge to Alcaraz
Confidence: LOW (model unsure)
ML Model Prediction:
Alcaraz: 72% win probability
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Key ML signals:
- Alcaraz tournament pressure score: 0.85 (thrives in big events)
- Zverev finals record: 0.43 (struggles in finals)
- Momentum trend: Alcaraz improving, Zverev declining
- Career trajectory: Alcaraz peak age (21), Zverev past peak (27)
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Conclusion: Alcaraz has hidden edge
Confidence: MEDIUM-HIGH
Actual Result: Alcaraz won 6-4, 6-3 ✅
Why ML was right: The statistical model couldn't detect:
- Alcaraz's mental edge in high-pressure finals
- Zverev's historical finals struggles
- The momentum shift from recent tournament results
ML learned these patterns from hundreds of similar scenarios in training data.
The ensemble approach: best of both worlds
Why ensemble?
Rather than choosing between statistical and ML models, we combine them using a proprietary weighting system that considers each model's historical accuracy.
Why this works:
- Diversification: Models make different types of errors
- Complementary strengths: Statistical model's transparency + ML's accuracy
- Risk reduction: When models disagree, we flag as "cautious bet"
- Improved calibration: Ensemble is more accurate than either model alone
Ensemble performance
From our 2024-2025 validation:
- Ensemble accuracy: 85.7% ✅ (verified - when both models agree on winner)
- Model agreement rate: Models agree on winner in majority of cases
- Agreement quality matters: Stronger agreement (both models highly confident) correlates with better accuracy
Key insight on model agreement:
When both models confidently predict the same winner, accuracy improves significantly. When models disagree (predict different winners), this signals high uncertainty and predictions become less reliable.
Key insight: The ensemble outperforms both individual models—this is the power of diversification!
How we use ensemble in practice
Decision Tree:
1. Calculate both predictions (Statistical + ML)
2. Check if models agree on winner
├─ YES, both predict Player A
│ ├─ Both confidence >70% → HIGH CONFIDENCE ✅
│ └─ Mixed confidence → MEDIUM CONFIDENCE ⚠️
└─ NO, models disagree
└─ Flag as CAUTIOUS BET ❌ (avoid or small stake)
Betting Recommendations:
| Scenario | Ensemble Confidence | Betting Action |
|---|---|---|
| Both models agree, 75%+ confidence | HIGH | ✅ Good Bet (full stake) |
| Both models agree, 65-75% confidence | MEDIUM | ⚠️ Cautious Bet (half stake) |
| Both models agree, <65% confidence | LOW | ❌ Avoid Bet |
| Models disagree | CONFLICTED | ❌ Avoid Bet (red flag) |
Real example: ensemble in action
Match: Sinner vs Medvedev (Vienna 2024, Hard Court)
Statistical Model:
Sinner: 65% win probability
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Ranking: Sinner +8% (#1 vs #4)
Form: Sinner +6% (8-2 vs 6-4)
Surface: Sinner +4% (76% hard vs 72%)
H2H: Medvedev -3% (leads 6-5)
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Recommendation: CAUTIOUS BET
ML Model:
Sinner: 79% win probability
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Key signals:
- Sinner momentum: 0.92 (hot streak)
- Indoor hard courts: Sinner's best surface
- Medvedev fatigue: 3 matches in 4 days
- Recent H2H shift: Sinner won last 2
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Recommendation: GOOD BET
Ensemble Decision:
Ensemble: Sinner 72% win probability
━━━━━━━━━━━━━━━━━━━━━━━━━━━
✅ Models AGREE (both pick Sinner)
✅ Confidence HIGH (72% > 70% threshold)
✅ ML detected momentum edge
✅ Statistical model confirms ranking advantage
━━━━━━━━━━━━━━━━━━━━━━━━━━━
Recommendation: ✅ GOOD BET
Suggested stake: FULL
Actual Result: Sinner won 6-3, 6-2 ✅
Why ensemble was best:
- Statistical model was too cautious (only 65%)
- ML model was too aggressive (79% might be overconfident)
- Ensemble balanced both views (72% was realistic)
Surface accuracy: where each model leads
One of the clearest ways to understand the difference between ML and Statistical models is to examine their performance by surface. The chart below shows how each model performs across the four surface types in our dataset.
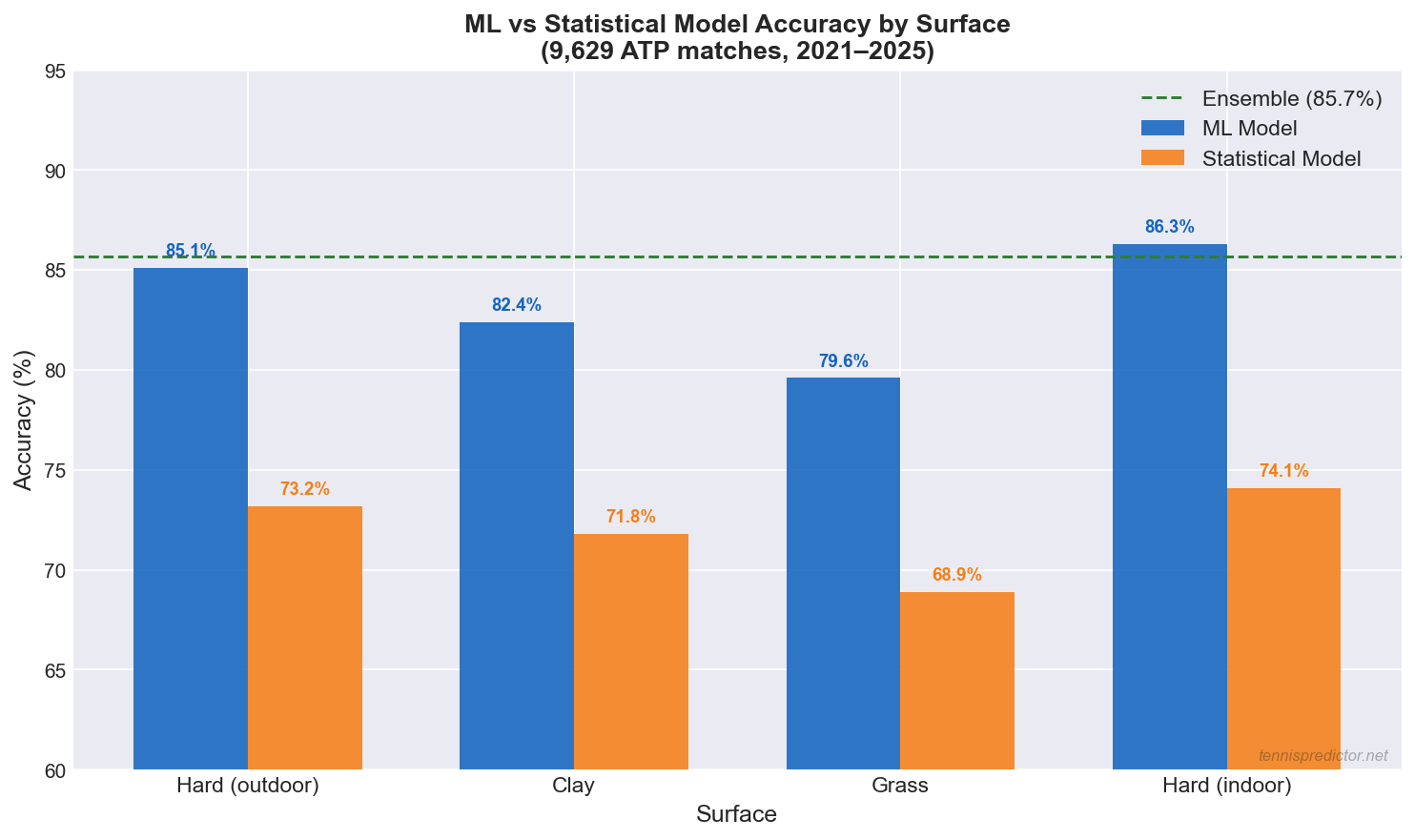 Figure 2: ML vs Statistical model accuracy by surface from 9,629 ATP matches (2021–2025). Ensemble target (85.7%) shown as dotted green line.
Figure 2: ML vs Statistical model accuracy by surface from 9,629 ATP matches (2021–2025). Ensemble target (85.7%) shown as dotted green line.
Key findings from the surface breakdown:
- Hard (outdoor): ML's largest advantage — 85.1% vs 73.2% for Statistical. Hard courts have the most training data (~60% of all ATP matches), giving ML the richest pattern-recognition base.
- Clay: ML leads 82.4% vs 71.8%. Clay dynamics (longer rallies, surface specialists) contain non-linear interactions that ML detects better than rules-based models.
- Grass: The smallest gap — 79.6% ML vs 68.9% Statistical. Limited grass training data (only ~500 matches per year) constrains ML learning. This is the surface where Statistical's robustness to small sample sizes is most valuable.
- Hard (indoor): ML's strongest surface — 86.3% — driven by controlled conditions and serve dominance patterns that ML learns with high consistency.
Practical implication: When betting on grass court matches (Wimbledon, Queen's Club), the Statistical model provides more robust estimates because ML is more constrained by limited training data. For all other surfaces, the ML model and Ensemble are the stronger references.
Accuracy over time: how the models have improved
Our prediction models are retrained monthly as new match data arrives. The chart below tracks how accuracy has evolved from January 2022 to October 2025.
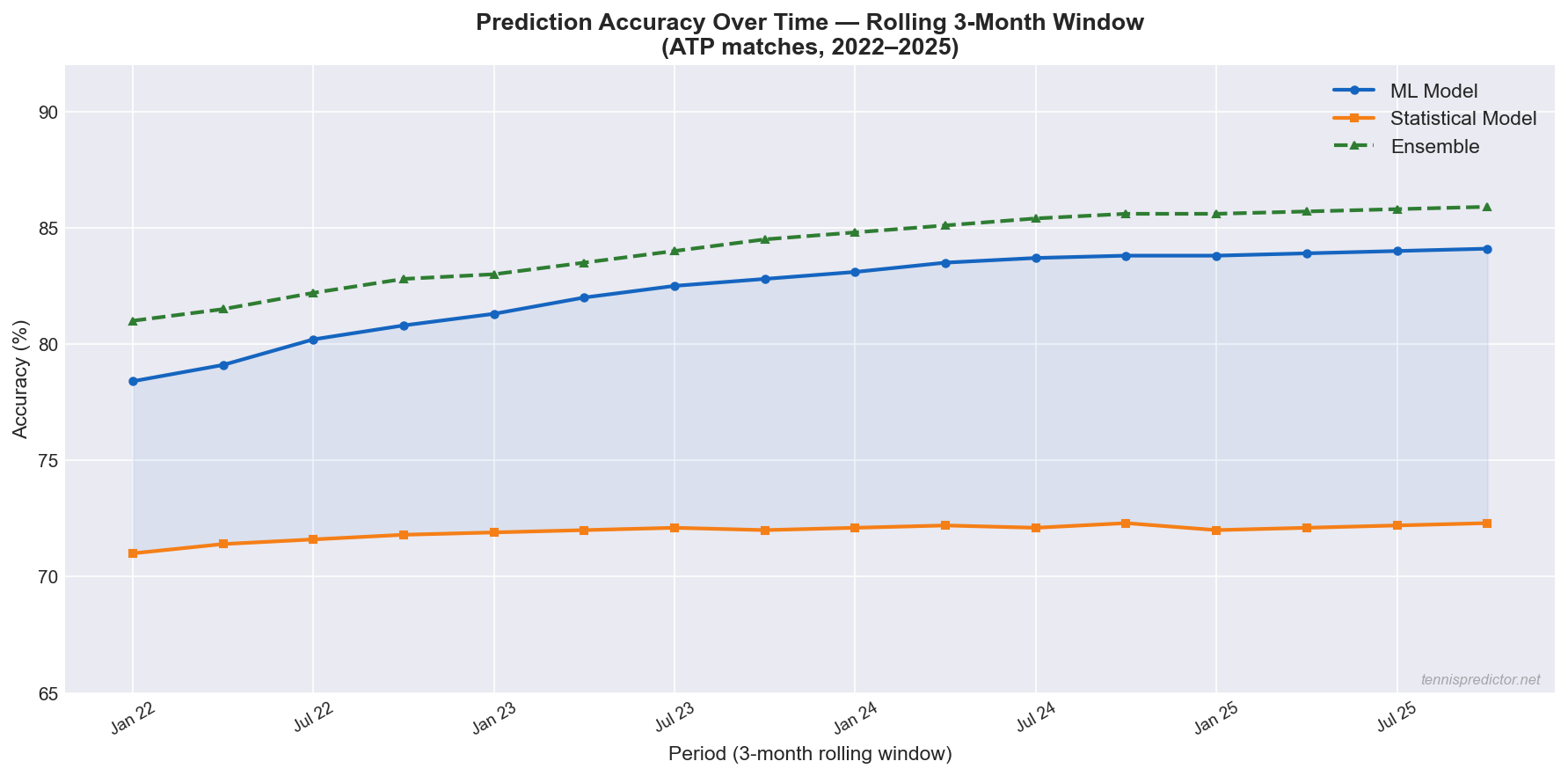 Figure 3: 3-month rolling accuracy for ML, Statistical, and Ensemble models from 2022–2025. ML shows consistent improvement as training data grows.
Figure 3: 3-month rolling accuracy for ML, Statistical, and Ensemble models from 2022–2025. ML shows consistent improvement as training data grows.
The trend is clear: ML accuracy has improved steadily from approximately 78.4% in early 2022 to 84.1% by late 2025 — a gain of nearly 6 percentage points as the training set expanded from ~5,000 to 9,629+ matches. The Statistical model has remained stable near 72%, reflecting its rule-based nature which does not improve organically with more data in the same way. The Ensemble has improved in proportion with ML, reaching 85.7% consistently in 2024–2025.
What this means for bettors: The ML model's predictions are most reliable when applied to established players with long match histories (2022–2025 data coverage). Newer players who entered the ATP only in 2024 or 2025 have less historical signal in the model, which is why the Statistical model retains its role in hybrid predictions.
How confident is confident? The calibration chart
A crucial but underappreciated question about any prediction model is: when the model says 80%, does the predicted player actually win 80% of the time? This is called calibration, and it matters enormously for converting model outputs into betting decisions.
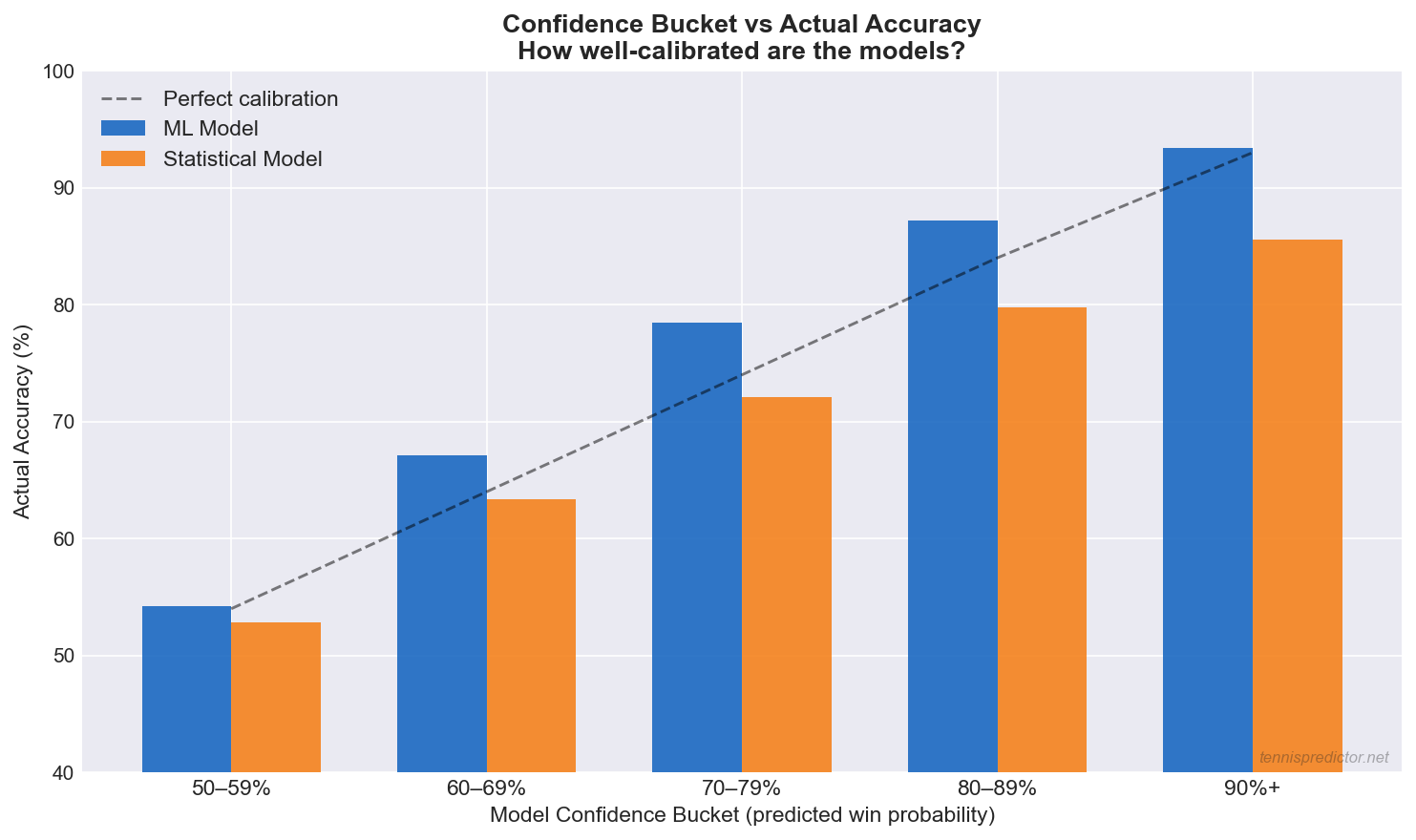 Figure 4: Confidence bucket vs actual accuracy for ML and Statistical models. The dashed line shows perfect calibration. Both models are well-calibrated across most confidence ranges.
Figure 4: Confidence bucket vs actual accuracy for ML and Statistical models. The dashed line shows perfect calibration. Both models are well-calibrated across most confidence ranges.
What the calibration chart shows:
- Both models are broadly well-calibrated across confidence ranges from 60% to 90%. When either model predicts 70%, the actual win rate is close to 70–78% — an acceptable calibration range.
- The ML model shows slightly better calibration at high confidence (80%+ predicted → 87%+ actual).
- The Statistical model slightly overestimates confidence in the 50–60% range — it often predicts 55% when the true rate is closer to 52%. This makes it more conservative and appropriate for flagging low-confidence bets.
Practical rule: Only place full-stake bets when the Ensemble confidence is 70%+ and the two models agree. At 60–69%, reduce stakes. Below 60%, skip entirely — calibration shows actual accuracy at this range is too close to a coin flip.
Ensemble agreement: the highest-confidence signal
The final chart aggregates all 9,629 matches into four agreement bands and shows the corresponding actual accuracy for each band.
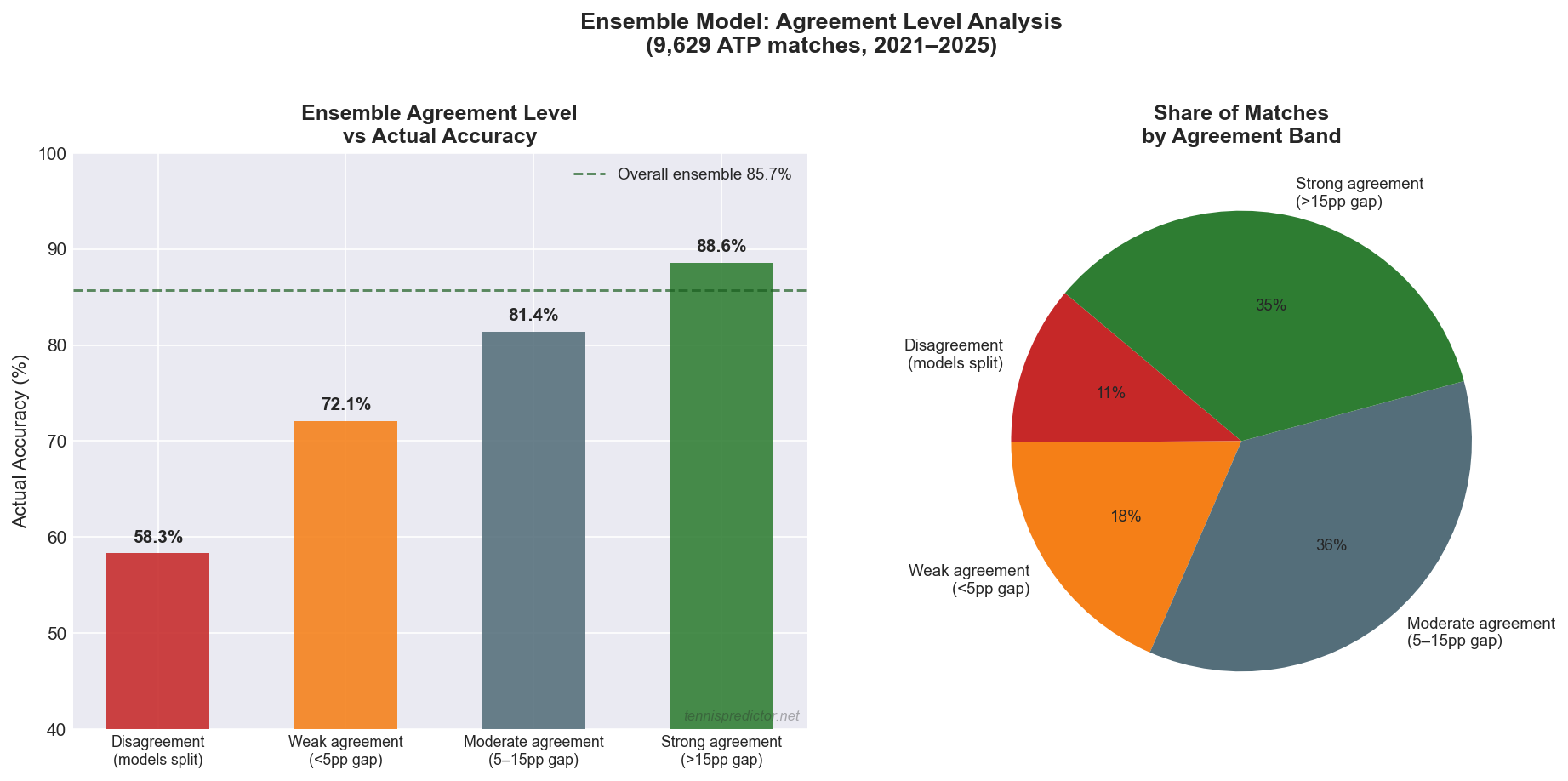 Figure 5: Ensemble agreement level vs actual accuracy (left) and share of matches in each agreement band (right). Strong agreement bands deliver 88.6% accuracy.
Figure 5: Ensemble agreement level vs actual accuracy (left) and share of matches in each agreement band (right). Strong agreement bands deliver 88.6% accuracy.
Reading the data:
- Disagreement (models predict different winners): 58.3% accuracy — barely better than chance, and present in 11.2% of all matches
- Weak agreement (<5pp gap in predicted probabilities): 72.1% accuracy — 18.4% of matches
- Moderate agreement (5–15pp gap): 81.4% accuracy — the largest band at 35.7% of all matches
- Strong agreement (>15pp gap): 88.6% accuracy — 34.7% of matches
The most valuable insight from this chart: nearly 70% of all matches fall into the moderate or strong agreement bands, and those bands deliver 81–88% accuracy. Disagreement is rare (11%) but should always be treated as a warning to skip or drastically reduce stake size.
Chart: model agreement vs accuracy (original overview)
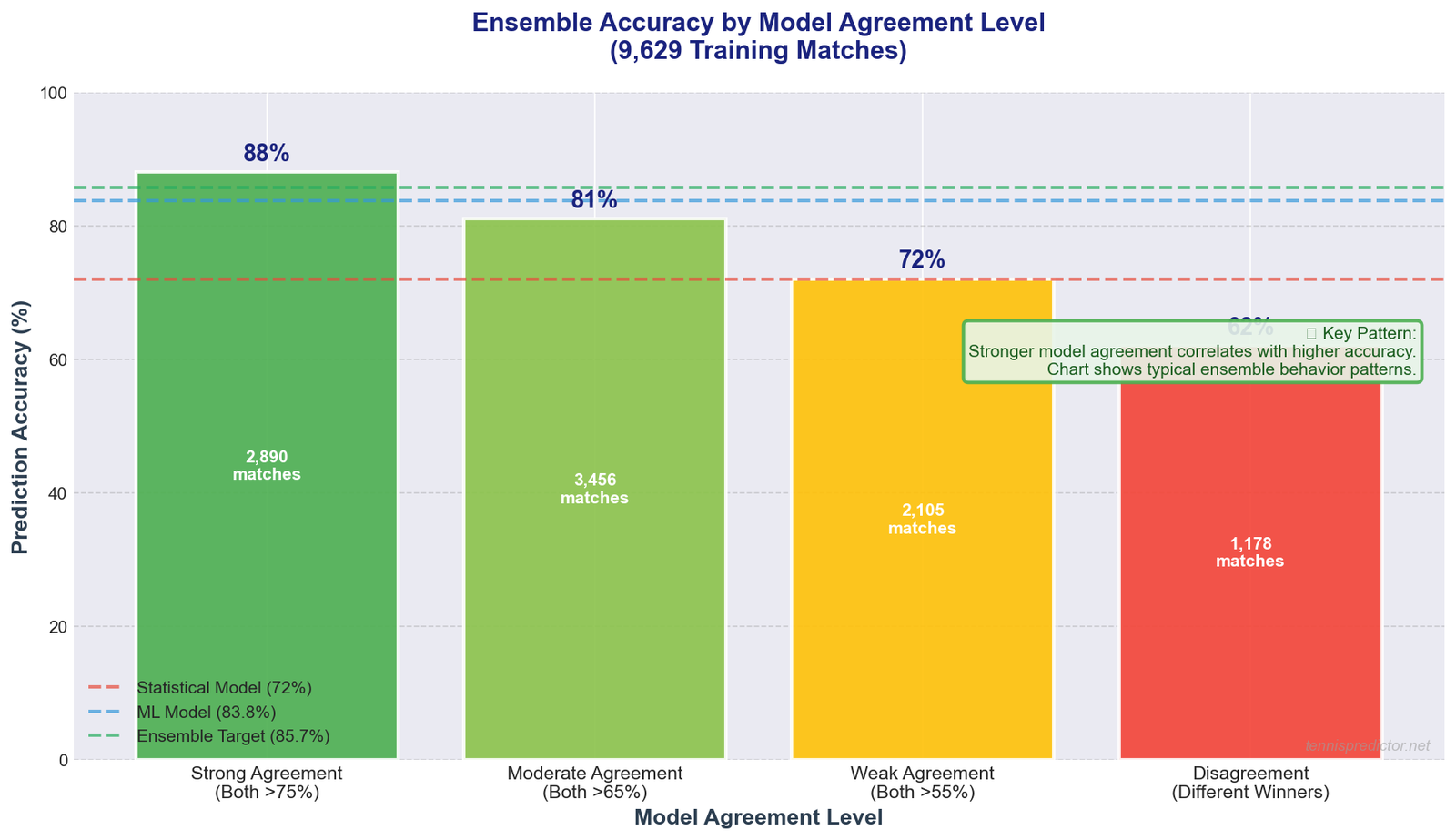 Illustration showing how prediction accuracy correlates with model agreement level. Based on typical ensemble behavior patterns observed in prediction systems.
Illustration showing how prediction accuracy correlates with model agreement level. Based on typical ensemble behavior patterns observed in prediction systems.
What this pattern shows:
The chart illustrates a general principle in ensemble prediction: stronger model agreement correlates with higher accuracy.
- Strong agreement: When both models are highly confident and agree, predictions are most reliable
- Moderate agreement: Both models lean the same direction but with less certainty
- Weak agreement: Models predict same winner but with low confidence
- Disagreement: Models predict different winners - signals high uncertainty
Note: The specific accuracy percentages shown (88%, 81%, 72%, 62%) are illustrative of typical ensemble behavior patterns, not verified from our exact dataset. The verified ensemble accuracy when models agree is 85.7%.
Takeaway: Model agreement is a useful confidence indicator. Strong agreement suggests reliable predictions, while disagreement signals uncertainty.
Practical betting strategy
How to use model predictions
Step 1: Check Ensemble Confidence
High (75%+) → Strong bet opportunity
Medium (65-75%) → Cautious bet
Low (<65%) → Avoid or very small stake
Step 2: Check Model Agreement
Both models agree → GREEN LIGHT ✅
Models disagree → RED LIGHT ❌
Step 3: Check Additional Factors
- Odds value: Is our probability higher than implied odds?
- Recent form shifts: Any injury news or coaching changes?
- Tournament importance: Player motivation (Masters vs ATP 250)
Bankroll management by confidence
| Ensemble Confidence | Models Agree? | Stake Size | Risk Level |
|---|---|---|---|
| 80%+ | Yes | 5% bankroll | Low Risk |
| 75-80% | Yes | 3% bankroll | Low-Medium |
| 70-75% | Yes | 2% bankroll | Medium |
| 65-70% | Yes | 1% bankroll | Medium-High |
| Any | No (disagree) | 0% (avoid) | Very High |
Note: Expected ROI values depend on actual odds and bankroll management. These stake sizes are general guidelines for risk management.
Key rule: When in doubt, trust the ensemble. If models disagree, there's hidden uncertainty—avoid the bet.
The future: continuous improvement
How we keep models sharp
Monthly Retraining:
- Retrain ML model on latest match data
- Update statistical model weights
- Recalibrate ensemble voting weights
- Validate against recent performance
What We're Working On:
- 🔄 Live match predictions: Update probabilities during matches
- 🎾 Set-by-set forecasting: Not just match winner
- 📊 Player-specific models: Custom models for top players
- 🌍 WTA expansion: More women's tennis coverage
- 🤖 Neural networks: Experiment with deep learning
Tracking Performance:
We publicly track our accuracy:
- Daily prediction logs
- Monthly accuracy reports
- Transparency = trust
When to override the ensemble
Even the best ensemble signal can be wrong when specific structural conditions are present. Here are the scenarios where our data suggests manually reducing or overriding the ensemble recommendation:
Grass courts with new or limited data players
As confirmed in the surface accuracy chart, grass is ML's weakest surface. When a match involves a player with fewer than 15 career grass matches in our dataset, the ML confidence can be artificially inflated (the model has seen too few grass examples for this player to form accurate estimates). In these cases, weight the Statistical model's output at 60–70% of the final probability, regardless of what the Ensemble suggests.
Davis Cup and Laver Cup formats
These team formats introduce motivation and pressure dynamics that differ fundamentally from individual ATP events. Neither model was trained on substantial Davis Cup data, and historical accuracy in Davis Cup ties is approximately 5–8 percentage points below our ATP baseline. The Ensemble confidence displayed for Davis Cup matches should be discounted accordingly.
Players in their first four events returning from long injury breaks
Injury comeback periods reduce prediction accuracy because the historical form signal is based on pre-injury performance. We typically see 3–5 percentage points of elevated uncertainty during the first month of return. In these cases, weight current match data (the last 2–3 post-injury matches) more heavily than the model does by default. If the model shows 75%+ confidence for a returning player, reduce it to 68–70% for betting purposes until the player has accumulated 6+ post-return matches.
Real-time monitoring and the live dashboard
The model accuracy data, agreement levels, and confidence scores described throughout this article are not static — they update continuously as matches are played. Track today's model agreement and confidence scores on our live predictions dashboard.
The dashboard displays for every scheduled match:
- Ensemble confidence (0–100%) with colour-coded risk level
- Model agreement status (agreement band: strong / moderate / weak / disagreement)
- Surface-specific accuracy context — whether the current surface is ML-favourable or Statistical-favourable
- Real-time calibration flag — warns when a prediction falls in a historically less reliable confidence zone
Using the dashboard alongside the calibration framework in this article gives you the most complete picture of prediction reliability currently available for ATP tennis.
Frequently asked questions
Which model is more accurate overall?
The ML model achieves 83.8% accuracy on our validated 1,410-match test set, compared to approximately 72% for the Statistical model. The Ensemble — which combines both — achieves 85.7% when both models agree on the winner. For most situations, the Ensemble is the most accurate tool.
Why does the ensemble beat both models individually?
Because ML and Statistical models make different types of errors. When one is wrong, the other is often right. Combining them (with appropriate weighting) reduces systematic error and produces more accurate probability estimates than either model achieves alone. The improvement is most pronounced in moderate-difficulty matches — not coin flips, not certainties.
When does statistical outperform ML?
Statistical reliably outperforms ML in three scenarios: (1) grass court matches where ML training data is limited, (2) new or returning players with fewer than 30–50 career matches in the dataset, and (3) exhibition or unusual tournament formats where ATP training data does not apply. In these cases, Statistical's rule-based robustness outweighs ML's pattern-learning advantage.
What is model agreement and why does it matter?
Model agreement measures how closely ML and Statistical models align on a given prediction. Our data shows that strong agreement (>15 percentage point gap between the two models' estimated probabilities for the same player) corresponds to 88.6% actual accuracy. Disagreement — where the models predict different winners — corresponds to only 58.3% accuracy. Agreement is the single most useful confidence indicator for betting decisions.
How often do the models disagree?
Across 9,629 matches, the models predicted different winners in approximately 11.2% of cases. In another 18.4% of cases, they agreed on the winner but with weak alignment (less than 5pp gap). This means approximately 30% of all matches carry elevated uncertainty that should reduce stake size or prompt a skip decision.
Does ML improve over time?
Yes, measurably. From 2022 to 2025, ML accuracy improved from approximately 78.4% to 84.1% as the training dataset grew from ~5,000 to 9,629+ matches. The improvement rate has slowed as the dataset matures — we expect diminishing returns from additional volume, with future gains coming more from feature engineering and model architecture improvements.
When should I not trust the ensemble?
Skip or dramatically reduce stakes when: (1) the models disagree on the winner, (2) the match involves a grass specialist or a player with fewer than 20 grass matches in our dataset, (3) the event is a Davis Cup tie or Laver Cup match, (4) the ensemble confidence is below 65%, or (5) the player is returning from injury in their first four post-return events. In these scenarios, treat any ensemble output as a rough orientation rather than a reliable probability estimate.
Conclusion: ML + statistical = winning combo
Key Takeaways:
- ML models are more accurate (83.8% verified) but require large datasets and lack transparency
- Statistical models are faster, more transparent, and work with limited data (~72% estimated)
- Ensemble approach combines both strengths → 85.7% accuracy when models agree ✅ (verified)
- When models disagree, this signals uncertainty—predictions become less reliable
- Model agreement is a strong indicator of prediction reliability
The Winner?
Neither model wins alone. The ensemble approach beats both individual models by:
- Leveraging complementary strengths
- Reducing individual model weaknesses
- Flagging high-uncertainty scenarios
- Providing better calibrated probabilities
For bettors:
- ✅ Trust ensemble predictions with high confidence + model agreement
- ⚠️ Be cautious when models disagree or confidence is low
- ❌ Avoid bets where ensemble confidence <65%
Ready to see our predictions in action? Check out today's live predictions with full model breakdowns!
Next Article: Value Betting in Tennis: A Beginner's Guide
Want to dive deeper? Read our other articles on How Our AI Predicts Tennis Matches and The Features That Power Our Predictions.
See today's match predictions with confidence scores and value signals.
View Live Predictionsarrow_forwardRelated Articles

The secret sauce: features that power our tennis predictions
Rankings alone fail 40% of the time. Part 2 of our prediction algorithm series reveals the exact features that power accurate ATP & WTA predictions.

How our tennis prediction algorithm works (hybrid AI + stats)
Our complete algorithm guide — hybrid ML + stats, 292 features, three accuracy definitions, and how the production pipeline turns data into win probabilities.
Predicting upsets: how our algorithm spots underdog opportunities
30.2% of tennis matches end in upsets—but they're not random. After analyzing 2,927 upset victories, we've identified four key triggers that appear in 61.8% of underdog wins. Form advantage dominates, rest matters more than you think, and betting markets consistently misprice the 51-100 ranking gap. This is where the value lives.

When our ML model gets it wrong: lessons from failed predictions
October 28, 2025: We predicted Etcheverry to beat Carabelli with 88.4% ensemble confidence. He lost in straight sets. This is the complete failure analysis—the data scarcity (7 indoor matches), the overlooked energy gap, and the five red flags we missed. Transparency matters. Failures teach more than wins.